Какие виды архитектур для разработки программного обеспечения вы знаете? Я бы ответил на этот вопрос, перечислив следующие архитектуры:
- N-Tier architecture
- Clean architecture
- Onion architecture
- Hexagonal Architecture
- Layered architecture
- Ports & Adapters architecture
- Vertical Slices architecture
- Event-Driven architecture
- SOA architecture
- Monolith architecture
- Microservices architecture
Наверное, я еще не все вспомнил и записал, поэтому пожалуйста напишите в комментариях, какие архитектуры я забыл упомянуть.
N-Tier Architecture
Слои — это способ разделения обязанностей и управления зависимостями. Каждый слой несет определенную ответственность. Более высокий уровень может использовать сервисы на более низком уровне, но не наоборот.
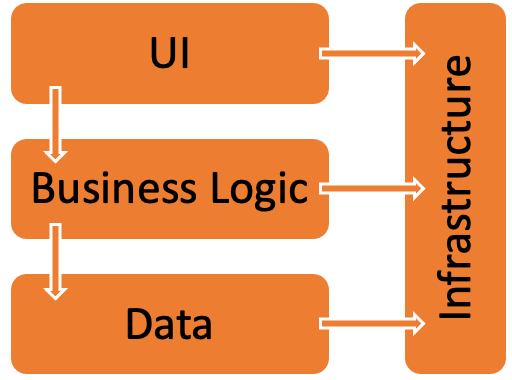
Уровни физически разделены и работают на отдельных машинах. Уровень может напрямую обращаться к другому уровню или использовать асинхронный обмен сообщениями (очередь сообщений). Хотя каждый слой может быть размещен на своем собственном уровне, это не обязательно. На одном уровне может размещаться несколько слоев. Физическое разделение уровней повышает масштабируемость и отказоустойчивость, но также увеличивает задержку от дополнительного сетевого взаимодействия.
Традиционное трехуровневое приложение имеет уровень представления, средний уровень и уровень базы данных. Средний уровень является необязательным. Более сложные приложения могут иметь более трех уровней. На приведенной выше схеме показано приложение с двумя средними уровнями, инкапсулирующими различные области функциональности.
Многоуровневое приложение может иметьархитектуру закрытого уровня или архитектуруоткрытого уровня:
В архитектуре закрытого слоя слой может вызвать следующий слой только сразу вниз.
В архитектуре открытого слоя слой может вызывать любой из слоев под ним.
Архитектура замкнутого уровня ограничивает зависимости между уровнями. Однако это может создать ненужный сетевой трафик, если один уровень просто передает запросы следующему уровню.
Подробнее про N-Tier Architecture.
Clean Architecture
Концепция чистой архитектуры была определена Робертом С. Мартином (MARTIN, 2017) в его книге под названием «Чистая архитектура: руководство ремесленника по структуре и дизайну программного обеспечения». В этой архитектуре системы можно разделить на два основных элемента: политики и детали. Политики — это бизнес-правила и процедуры, а подробные сведения — это элементы, необходимые для выполнения политик. (МАРТИН, 2017) Именно из этого подразделения Clean Architecture начинает дифференцировать себя от других архитектурных шаблонов. Архитектор должен создать способ для системы распознавать политики как основные элементы системы, а детали как не имеющие отношения к политикам.
В чистой архитектуре не обязательно выбирать базу данных или фреймворк в начале разработки, так как все это детали, которые не мешают политикам и, следовательно, могут быть изменены со временем.
Разделение слоев
В Clean Architecture есть четко определенное разделение слоев. Архитектура является фреймворк-независимой, т.е. внутренние слои, содержащие бизнес-правила, не зависят от какой-либо сторонней библиотеки, что позволяет разработчику использовать фреймворк в качестве инструмента и не адаптировать систему под спецификации конкретной технологии. Другими преимуществами Clean Architecture являются: тестируемость, независимость пользовательского интерфейса, независимость от базы данных и независимость от любых внешних агентов (бизнес-правила не должны ничего знать об интерфейсах внешнего мира).
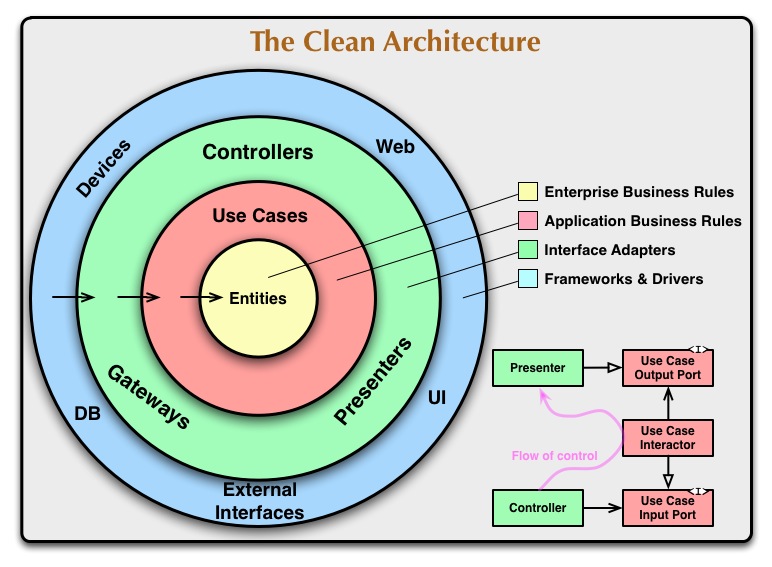
Каждый слой на рисунке представляет собой отдельную область программного обеспечения, самой внутренней частью которой являются политики, а самой внешней - механизмы.
Основным правилом для Clean Architecture является правило зависимостей, которое гласит, что зависимости исходного кода могут указывать только внутрь, то есть в направлении политик самого высокого уровня. Тем не менее, мы можем сказать, что элементы самого внутреннего слоя не могут иметь никакой информации об элементах самого внешнего слоя. Классы, функции, переменные, формат данных или любая сущность, объявленная на внешнем уровне, не должны упоминаться в коде внутреннего слоя.
Самым внутренним уровнем является уровень Сущностей, который содержит бизнес-цели приложения, содержащие правила самого общего и самого высокого уровня. Сущность может быть набором структур данных и функций или объектом с методами, если эта сущность может использоваться несколькими приложениями. Этот слой не должен быть изменен изменениями в самых внешних слоях, то есть никакие операционные изменения в любом приложении не должны влиять на этот слой.
Уровень вариантов использования содержит бизнес-правила, специфичные для приложения, группирующие и реализующие все варианты использования системы. Сценарии использования организуют поток данных, в сущности, и из них и направляют сущности в применении важнейших бизнес-правил для достижения целей вариантов использования. Этот слой также не должен затрагиваться самыми внешними слоями, и изменения не должны влиять на слой сущностей. Однако если детали варианта использования изменятся, это повлияет на часть кода на этом уровне.
Слой адаптеров интерфейса имеет набор адаптеров, которые преобразуют данные в наиболее удобный формат для слоев вокруг него. Другими словами, он берет данные из базы данных, например, и преобразует их в наиболее удобный формат для уровней сущностей и вариантов использования. Также может быть выполнен обратный путь преобразования, от данных из самых внутренних слоев в самые внешние слои. Докладчики, представления и контроллеры относятся к этому уровню.
Самый внешний слой диаграммы обычно состоит из фреймворков и баз данных. Этот уровень содержит код, который устанавливает связь с уровнем адаптеров интерфейса. Все детали находятся в этом слое, Веб — это деталь, база данных — это деталь. Все эти элементы расположены в самом внешнем слое, чтобы избежать риска вмешательства в другие (MARTIN, 2017).
Но если слои настолько независимы, как они общаются? Это противоречие разрешается с помощью принципа инверсии зависимостей. Роберт С. МАРТИН (2017) объясняет, что можно организовать интерфейсы и отношения наследования таким образом, чтобы зависимости исходного кода находились напротив потока управления в нужных точках.
Если варианту использования необходимо взаимодействовать с докладчиком, этот вызов не может быть простым, поскольку он нарушает правило зависимостей, поэтому вариант использования вызывает интерфейс из внутреннего слоя, а презентатор во внешнем круге выполняет реализацию. Этот метод может быть использован между всеми уровнями архитектуры. Данные, которые перемещаются между слоями, могут быть базовыми структурами или простыми объектами передачи данных, причем эти данные являются просто аргументами для вызовов функций. Сущности или записи из баз данных не должны передаваться, чтобы не нарушать правило зависимостей.
Onion Architecture
Эта архитектура очень похожа на Clean Architecture.
Hexagonal Architecture
Эта архитектура очень похожа на Clean Architecture.
Ports & Adapters Architecture
Эта архитектура очень похожа на Clean Architecture.
Vertical Slices Architecture
Архитектура, которую предложил Джимми Богард. Так что же такое «архитектура вертикальных срезов»? В этом стиле моя архитектура построена вокруг отдельных запросов, инкапсулируя и группируя все проблемы от внешнего интерфейса до задней части. Вы берете обычную «n-ярусную» или шестиугольную / любую другую архитектуру и удаляете ворота и барьеры через эти слои и соединяетесь вдоль оси изменения:
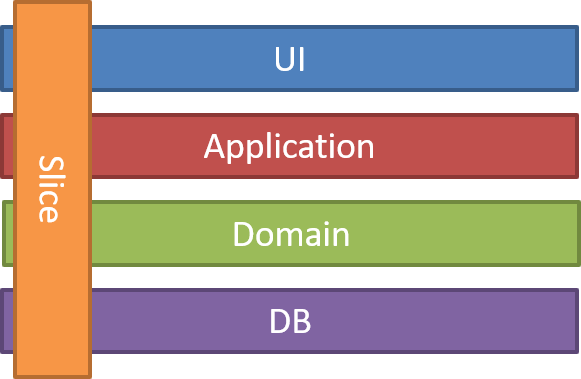
При добавлении или изменении объекта в приложении я обычно касаюсь множества различных «слоев» в приложении. Я изменяю пользовательский интерфейс, добавляю поля в модели, изменяю проверку и так далее. Вместо того, чтобы соединяться по слою, мы соединяем вертикально вдоль среза. Сведите к минимуму связь между фрагментами и максимизируйте связь в срезе.
При таком подходе большинство абстракций тают, и нам не нужны какие-либо «общие» абстракции слоев, такие как репозитории, сервисы, контроллеры. Иногда это все еще требуется нашим инструментам (например, контроллерам или единицам работы ORM), но мы сводим к минимуму совместное использование логики кросс-слайса.
При таком подходе каждый из наших вертикальных срезов может решить для себя, как наилучшим образом выполнить запрос:

Старые шаблоны логики домена из книги «Шаблоны архитектуры предприятия» больше не должны быть выбором для всего приложения. Вместо этого мы можем начать с простого (Transaction Script) и просто рефакторить шаблоны, которые возникают из запахов кода, которые мы видим в бизнес-логике. Новые функции только добавляют код, вы не меняете общий код и не беспокоитесь о побочных эффектах. Очень раскрепощает!
Однако у этого подхода есть некоторые недостатки, поскольку он предполагает, что ваша команда понимает запахи кода и рефакторинг. Если ваша команда не понимает, когда «сервис» делает слишком много, чтобы отправить логику в домен, этот шаблон, скорее всего, не для вас.
Если ваша команда понимает рефакторинг и может понять, когда вставлять сложную логику в домен, в то, какими должны были быть сервисы DDD, и знакома с другими методами рефакторинга Фаулера/Кериевского, вы обнаружите, что этот стиль архитектуры способен масштабироваться далеко за пределы традиционных многоуровневых / концентрических архитектур.
Подобнее Vertical Slice Architecture (jimmybogard.com)
Event-Driven Architecture
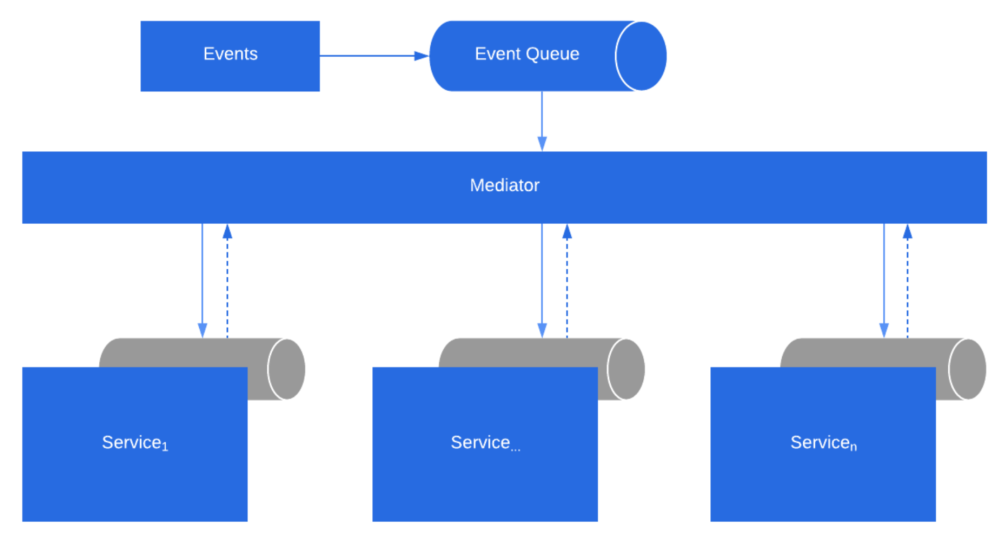
События доставляются почти в режиме реального времени, поэтому потребители могут немедленно реагировать на события по мере их возникновения. Производители отделены от потребителей — производитель не знает, какие потребители слушают. Потребители также отделены друг от друга, и каждый потребитель видит все события. Это отличается от шаблона конкурирующих потребителей, где потребители извлекают сообщения из очереди, а сообщение обрабатывается только один раз (при условии отсутствия ошибок). В некоторых системах, таких как IoT, события должны приниматься в очень больших объемах.
Архитектура, управляемая событиями, может использовать модель публикации/подписки (также называемую pub/sub) или модель потока событий.
Pub/sub: инфраструктура обмена сообщениями отслеживает подписки. Когда событие публикуется, оно отправляется каждому подписчику. После получения события его нельзя воспроизвести, и новые подписчики не видят его.
Потоковая передача событий: события записываются в журнал. События строго упорядочены (внутри раздела) и долговечны. Клиенты не подписываются на поток, вместо этого клиент может читать из любой части потока. Клиент несет ответственность за продвижение своей позиции в потоке. Это означает, что клиент может присоединиться в любое время и воспроизводить события.
Со стороны потребителя есть некоторые распространенные вариации:
Простая обработка событий. Событие немедленно инициирует действие в потребителе. Например, можно использовать Функции Azure с триггером служебной шины, чтобы функция выполнялась всякий раз, когда сообщение публикуется в разделе Служебной шины.
Комплексная обработка событий. Потребитель обрабатывает ряд событий, ища закономерности в данных событий, используя такую технологию, как Azure Stream Analytics или Apache Storm. Например, можно агрегировать показания встроенного устройства в течение временного окна и генерировать уведомление, если скользящая средняя пересекает определенное пороговое значение.
Обработка потока событий. Используйте платформу потоковой передачи данных, такую как Центр Интернета вещей Azure или Apache Kafka, в качестве конвейера для приема событий и передачи их потоковым процессорам. Потоковые процессоры действуют для обработки или преобразования потока. Для разных подсистем приложения, может быть, несколько потоковых процессоров. Такой подход хорошо подходит для рабочих нагрузок Интернета вещей.
Источник событий может быть внешним по отношению к системе, например физические устройства в решении IoT. В этом случае система должна иметь возможность принимать данные на томе и пропускная способность, требуемая источником данных.
На приведенной выше логической схеме каждый тип потребителя показан в виде одного поля. На практике принято иметь несколько экземпляров потребителя, чтобы потребитель не стал единой точкой отказа в системе. Для обработки объема и частоты событий также может потребоваться несколько экземпляров. Кроме того, один потребитель может обрабатывать события в нескольких потоках. Это может создать проблемы, если события должны обрабатываться по порядку или требовать точно однократной семантики
Подробнее Event-driven architecture style - Azure Architecture Center | Microsoft Learn
SOA architecture
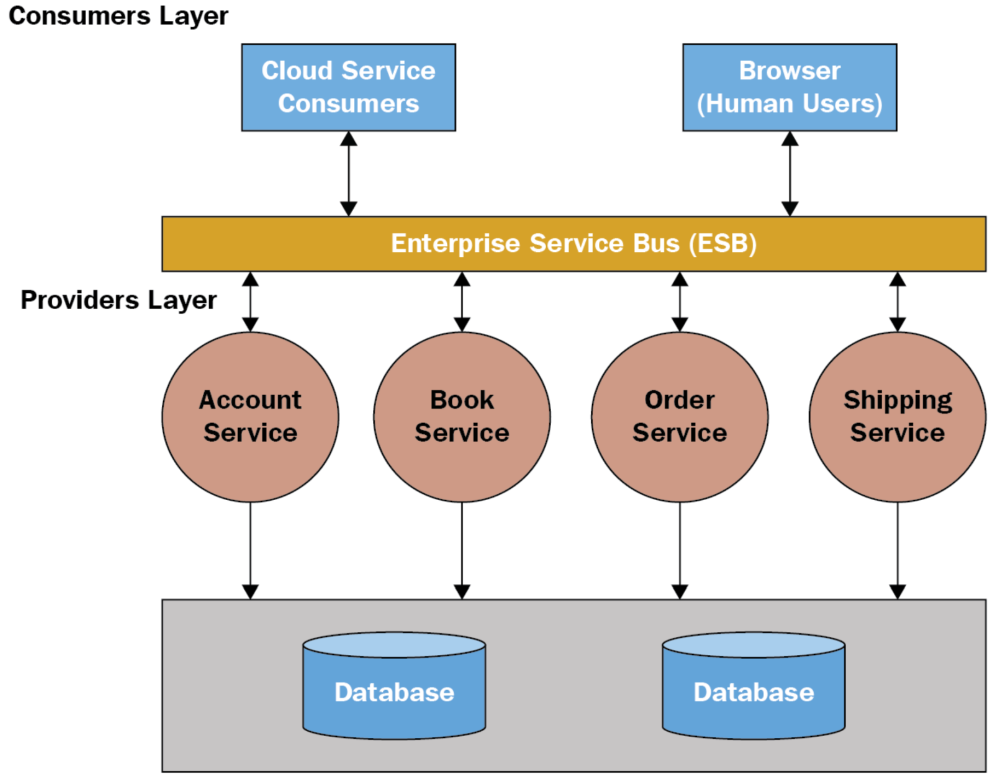
Сервис-ориентированная архитектура (SOA) — это стиль проектирования программного обеспечения, при котором услуги предоставляются другим компонентам компонентами приложения через протокол связи по сети. Его принципы не зависят от поставщиков и других технологий. В сервис-ориентированной архитектуре ряд сервисов взаимодействуют друг с другом одним из двух способов: через передачу данных или через два или более сервисов, координирующих деятельность. Это лишь одно из определений сервис-ориентированной архитектуры.
Monolithic architecture
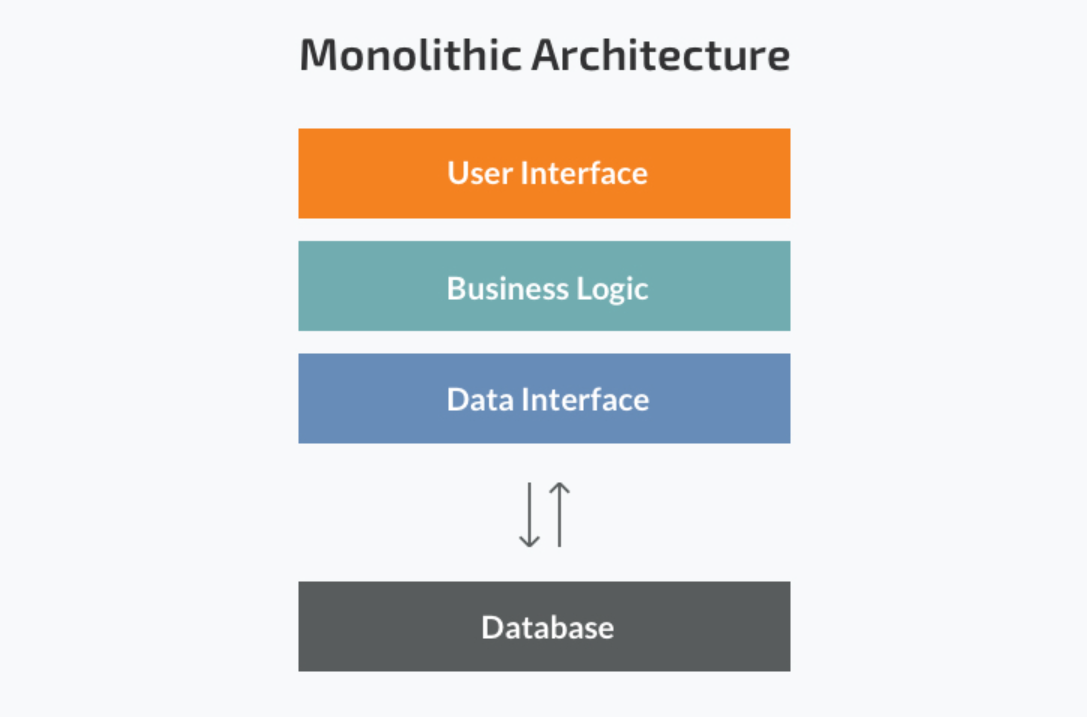
Монолитное программное обеспечение спроектировано как автономное, при этом компоненты или функции программы тесно связаны, а неслабо связаны, как в модульных программах. В монолитной архитектуре каждый компонент и связанные с ним компоненты должны присутствовать для выполнения и компиляции кода и для запуска программного обеспечения.
Монолитные приложения являются одноуровневыми, что означает, что несколько компонентов объединяются в одно большое приложение. Следовательно, они, как правило, имеют большие кодовые базы, которые могут быть громоздкими для управления с течением времени.
Кроме того, если один программный компонент должен быть обновлен, другие элементы также могут потребовать переписывания, и все приложение должно быть перекомпилировано и протестировано. Процесс может занять много времени и может ограничить гибкость и скорость команд разработчиков программного обеспечения. Несмотря на эти проблемы, этот подход все еще используется, поскольку он предлагает некоторые преимущества. Кроме того, многие ранние приложения были разработаны как монолитное программное обеспечение, поэтому подход нельзя полностью игнорировать, когда эти приложения все еще используются и требуют обновлений.
Плюсы и минусы
Это решение имеет ряд преимуществ:
- Простота разработки - целью современных средств разработки и IDE является поддержка разработки монолитных приложений
- Простота развертывания - вам просто нужно развернуть WAR-файл (или иерархию каталогов) в соответствующей среде выполнения
- Простота масштабирования — можно масштабировать приложение, запустив несколько копий приложения за балансировщиком нагрузки
Однако, как только приложение становится большим, а команда увеличивается в размерах, этот подход имеет ряд недостатков, которые становятся все более существенными:
- Большая монолитная кодовая база пугает разработчиков, особенно новичков в команде. Приложение может быть трудно понять и изменить. В результате развитие обычно замедляется. Кроме того, поскольку нет жестких границ модулей, модульность со временем разрушается. Более того, поскольку может быть трудно понять, как правильно реализовать изменение, качество кода со временем снижается. Это нисходящая спираль.
- Перегруженная IDE - чем больше кодовая база, тем медленнее IDE и тем менее продуктивны разработчики.
- Перегруженный веб-контейнер - чем больше приложение, тем больше времени требуется для запуска. Это оказало огромное влияние на производительность разработчиков из-за времени, потраченного впустую в ожидании запуска контейнера. Это также влияет на развертывание.
- Непрерывное развертывание затруднено - большое монолитное приложение также является препятствием для частых развертываний. Чтобы обновить один компонент, необходимо повторно развернуть все приложение. Это будет прерывать фоновые задачи (например, задания Quartz в Приложении Java), независимо от того, влияют ли они на изменение, и, возможно, вызовет проблемы. Существует также вероятность того, что компоненты, которые не были обновлены, не будут запускаться правильно. В результате возрастает риск, связанный с перераспределением, что препятствует частым обновлениям. Это особенно проблематично для разработчиков пользовательского интерфейса, так как им обычно требуется быстрая итерация и частое повторное развертывание.
- Масштабирование приложения может быть затруднено — монолитная архитектура заключается в том, что она может масштабироваться только в одном измерении. С одной стороны, он может масштабироваться с увеличением объема транзакций за счет запуска большего количества копий приложения. Некоторые облака могут даже динамически настраивать количество экземпляров в зависимости от нагрузки. Но, с другой стороны, эта архитектура не может масштабироваться с увеличением объема данных. Каждая копия экземпляра приложения будет получать доступ ко всем данным, что делает кэширование менее эффективным и увеличивает потребление памяти и трафик ввода-вывода. Кроме того, различные компоненты приложения имеют разные требования к ресурсам - один может интенсивно использовать ЦП, а другой - память. С монолитной архитектурой мы не можем масштабировать каждый компонент независимо друг от друга.
- Препятствие для масштабирования разработки - Монолитное приложение также является препятствием для масштабирования разработки. Как только приложение достигает определенного размера, полезно разделить инженерную организацию на команды, которые сосредоточены на конкретных функциональных областях. Например, мы можем захотеть иметь команду пользовательского интерфейса, бухгалтерскую группу, команду инвентаризации и т. Д. Проблема с монолитным приложением заключается в том, что оно мешает командам работать независимо. Группы должны координировать свои усилия в области развития и перераспределения должностей. Команде гораздо сложнее внести изменения и обновить производство.
- Требует долгосрочной приверженности технологическому стеку - монолитная архитектура заставляет вас быть женатым на стеке технологий (а в некоторых случаях и на определенной версии этой технологии), Вы выбрали в начале разработки. При монолитном применении может быть трудно постепенно принять более новую технологию. Например, давайте представим, что вы выбрали JVM. У вас есть несколько вариантов языка, поскольку, наряду с Java, вы можете использовать другие языки JVM, которые хорошо взаимодействуют с Java, такие как Groovy и Scala. Но компоненты, написанные на языках, отличных от JVM, не имеют места в вашей монолитной архитектуре. Кроме того, если приложение использует платформу платформы, которая впоследствии устаревает, может быть сложно постепенно перенести приложение на более новую и лучшую платформу. Вполне возможно, что для того, чтобы принять более новую платформу, вам придется переписать все приложение, что является рискованным предприятием.
Microservices architecture
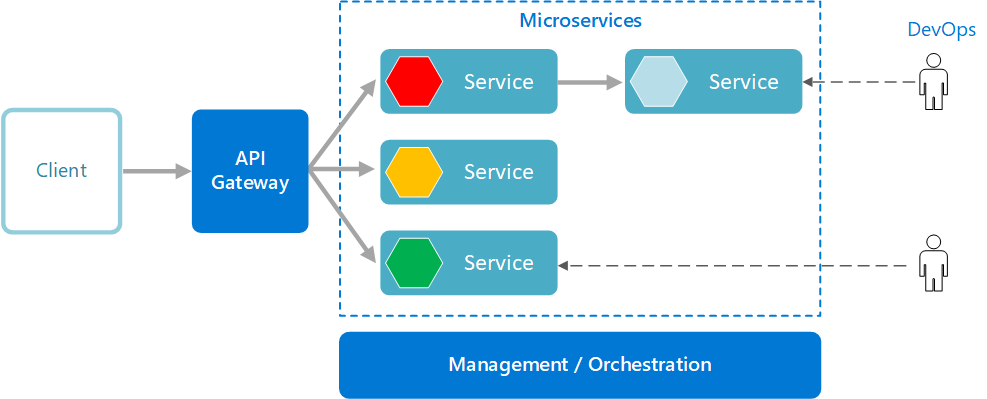
Что такое микросервисы
- Микрослужбы являются небольшими, независимыми и слабо связанными. Одна небольшая команда разработчиков может писать и поддерживать сервис.
- Каждый сервис представляет собой отдельную кодовую базу, которой может управлять небольшая команда разработчиков.
- Службы можно развертывать независимо друг от друга. Группа может обновить существующую службу без перестроения и повторного развертывания всего приложения.
- Службы несут ответственность за сохранение своих собственных данных или внешнего состояния. Это отличается от традиционной модели, где отдельный слой данных обрабатывает сохраняемость данных.
- Службы взаимодействуют друг с другом с помощью четко определенных API. Внутренние сведения о реализации каждой службы скрыты от других служб.
- Поддерживает программирование полиглотов. Например, службам не нужно совместно использовать один и тот же стек технологий, библиотеки или платформы.
Помимо самих сервисов, в типичной архитектуре микрослужб появляются и другие компоненты:
Управление/оркестровка. Этот компонент отвечает за размещение служб на узлах, выявление сбоев, перебалансировку служб между узлами и т. д. Как правило, этот компонент представляет собой готовую технологию, такую как Kubernetes, а не что-то специально созданное.
Шлюз API. Шлюз API является точкой входа для клиентов. Вместо прямого вызова служб клиенты вызывают шлюз API, который перенаправляет вызов соответствующим службам на серверной части.
Преимущества использования шлюза API:
- Это отделяет клиентов от услуг. Службы могут быть версированы или переработаны без необходимости обновления всех клиентов.
- Службы могут использовать протоколы обмена сообщениями, которые не являются веб-дружественными, такие как AMQP.
- Шлюз API может выполнять другие сквозные функции, такие как проверка подлинности, ведение журнала, завершение SSL и балансировка нагрузки.
- Готовые политики, например для регулирования, кэширования, преобразования или проверки.
Преимущества
- Подвижность. Поскольку микрослужбы развертываются независимо, управлять исправлениями ошибок и выпусками функций проще. Можно обновить службу без повторного развертывания всего приложения и выполнить откат обновления, если что-то пойдет не так. Во многих традиционных приложениях, если ошибка обнаружена в одной части приложения, она может заблокировать весь процесс выпуска. Новые функции могут быть отложены в ожидании исправления ошибок, которые будут интегрированы, протестированы и опубликованы.
- Небольшие, сфокусированные команды. Микрослужба должна быть достаточно маленькой, чтобы одна специализированная группа могла ее создавать, тестировать и развертывать. Небольшие размеры команды повышают гибкость. Большие команды, как правило, менее продуктивны, потому что общение происходит медленнее, накладные расходы на управление растут, а гибкость снижается.
- Небольшая кодовая база. В монолитном приложении существует тенденция со временем к запутыванию зависимостей кода. Добавление новой функции требует касания кода во многих местах. Не предоставляя общего доступа к коду или хранилищам данных, архитектура микрослужб сводит к минимуму зависимости, что упрощает добавление новых функций.
- Сочетание технологий. Команды могут выбрать технологию, которая наилучшим образом соответствует их сервису, используя сочетание стеков технологий по мере необходимости.
- Изоляция неисправностей. Если отдельная микрослужба становится недоступной, она не нарушит работу всего приложения, если все вышестоящие микрослужбы предназначены для правильной обработки сбоев. Например, можно реализоватьшаблон автоматического выключателя или спроектировать решение таким образом, чтобы микрослужбы взаимодействовали друг с другом с помощьюасинхронных шаблонов обмена сообщениями.
- Масштабируемость. Службы можно масштабировать независимо друг от друга, что позволяет масштабировать подсистемы, требующие дополнительных ресурсов, без горизонтального масштабирования всего приложения. С помощью оркестратора, такого как Kubernetes или Service Fabric, можно упаковать более высокую плотность служб на одном узле, что позволяет более эффективно использовать ресурсы.
- Изоляция данных. Гораздо проще выполнять обновления схемы, поскольку затрагивается только одна микрослужба. В монолитном приложении обновления схемы могут стать очень сложными, поскольку разные части приложения могут касаться одних и тех же данных, что делает любые изменения в схеме рискованными.
Проблемы
Преимущества микросервисов не предоставляются бесплатно. Вот некоторые из проблем, которые следует рассмотреть, прежде чем приступать к архитектуре микрослужб.
- Сложность. Приложение микрослужб имеет больше движущихся частей, чем эквивалентное монолитное приложение. Каждый сервис проще, но вся система в целом сложнее.
- Разработка и тестирование. Написание небольшого сервиса, который опирается на другие зависимые службы, требует иного подхода, чем написание традиционного монолитного или многоуровневого приложения. Существующие инструменты не всегда предназначены для работы с зависимостями служб. Рефакторинг через границы служб может быть затруднен. Также сложно тестировать зависимости служб, особенно когда приложение быстро развивается.
- Отсутствие управления. Децентрализованный подход к созданию микросервисов имеет преимущества, но он также может привести к проблемам. Вы можете получить так много разных языков и фреймворков, что приложение становится трудно поддерживать. Возможно, было бы полезно установить некоторые общепроектные стандарты, не слишком ограничивая гибкость команд. Это особенно относится к сквозным функциям, таким как ведение журнала.
- Перегрузка сети и задержка. Использование множества небольших, детализированных служб может привести к большему количеству межсервисной связи. Кроме того, если цепочка зависимостей службы становится слишком длинной (служба A вызывает B, которая вызывает C...), дополнительная задержка может стать проблемой. Вам нужно будет тщательно проектировать API. Избегайте чрезмерно болтливых API, подумайте о форматах сериализации и найдите места для использования асинхронных шаблонов связи, таких каквыравнивание нагрузки на основе очереди.
- Целостность данных. При этом каждая микрослужба отвечает за собственную сохраняемость данных. В результате согласованность данных может стать проблемой. Примите возможную последовательность, где это возможно.
- Менеджмент. Чтобы добиться успеха с микрослужбами, требуется зрелая культура DevOps. Коррелированное ведение журнала между службами может быть сложной задачей. Как правило, ведение журнала должно коррелировать несколько вызовов служб для одной пользовательской операции.
- Управление версиями. Обновления службы не должны нарушать работу зависящих от нее служб. Несколько служб могут обновляться в любой момент времени, поэтому без тщательного проектирования у вас могут возникнуть проблемы с обратной или прямой совместимостью.
- Набор навыков. Микросервисы — это высокораспределенные системы. Тщательно оцените, есть ли у команды навыки и опыт, чтобы быть успешной.
Рекомендации
- Моделирование сервисов вокруг бизнес-домена.
- Децентрализуйте все. Отдельные команды отвечают за проектирование и строительство услуг. Избегайте совместного использования кода или схем данных.
- Хранение данных должно быть частным для службы, которой принадлежат данные. Используйте лучшее хранилище для каждой службы и типа данных.
- Службы взаимодействуют через хорошо продуманные API. Избегайте утечки деталей реализации. API должны моделировать домен, а не внутреннюю реализацию службы.
- Избегайте связи между службами. Причины связи включают общие схемы баз данных и жесткие протоколы связи.
- Переложите сквозные проблемы, такие как проверка подлинности и завершение SSL, на шлюз.
- Храните знания о домене вне шлюза. Шлюз должен обрабатывать и маршрутизировать клиентские запросы без знания бизнес-правил или логики домена. В противном случае шлюз становится зависимым и может вызвать связь между службами.
- Службы должны иметь слабую связь и высокую функциональную сплоченность. Функции, которые могут измениться вместе, должны быть упакованы и развернуты вместе. Если они находятся в отдельных службах, эти службы в конечном итоге тесно связаны, потому что изменение одной службы потребует обновления другой службы. Чрезмерно болтливое общение между двумя службами может быть симптомом тесной связи и низкой сплоченности.
- Изолируйте сбои. Используйте стратегии отказоустойчивости, чтобы предотвратить каскадирование сбоев в службе.
Подробнее можно посмотреть Microsoft Microservice architecture style - Azure Architecture Center | Microsoft Learn
Секрет
Полагаю, что вы знаете, но может быть для вас это будет сюрпризом, что невозможно (или почти невозможно) при разработке программного обеспечения в большом и сложном проекте использовать только одну (или даже только две) архитектуру. Да, да, да! Всегда применяются больше, чем одна архитектура. И тут вопрос в том, на сколько умело вы ими пользуетесь при решение тех или иных проблем. Другими словами, решая проблему (какую-то "боль"), которая возможно существует в вашей система, или может быть, реализуя какие-либо требования, поставленные перед вами и вашей командой, очень трудно использовать только один тип архитектуры.