24 сентября была представлена первая редакция CTP выпуска SQL Server 2019, и, позвольте сказать, что он переполнен всевозможными улучшениями и новыми возможностями (многие из которых можно найти в форме предварительного просмотра в базе данных SQL Azure). У меня была исключительная возможность познакомиться с этим чуть раньше, позволившая мне расширить представление об изменениях, пусть даже поверхностно. Вы можете также ознакомиться с последними публикациями от команды разработчиков SQL Server и обновленной документацией.
Не вдаваясь в подробности, я собираюсь обсудить следующие новые функций ядра: производительность, поиск и устранение неполадок в работе, безопасность, доступность и разработка. На данный момент у меня есть немного больше подробностей, чем у других, и часть из них уже подготовлена к публикациям. Я вернусь к этому разделу, как и к множеству других статей и документации и опубликую их. Спешу сообщить, что это не всеобъемлющий обзор, а только часть функционала, которую я успел «пощупать», вплоть до CTP 2.0. Еще есть много всего, о чем стоит рассказать.
Производительность
Табличные переменные: отложенное построение плана
За табличными переменными закрепилась не очень хорошая репутация, по большей части в области оценки стоимости. По умолчанию, SQL Server предполагает, что табличная переменная может содержать только одну строку, что порой приводит к неадекватному выбору плана, когда в переменной будет содержаться в разы больше строк. В качестве обходного решения обычно используется OPTION (RECOMPILE), но это требует изменения кода и расточительно, по отношению к ресурсам — выполнять перестроение каждый раз, в то время, как количество строк, чаще всего, одно и то же. Для эмуляции перестроения был введен флаг трассировки 2453, но он тоже требует запуск с флагом, и срабатывает только когда происходит существенное изменение в строках.
В уровне совместимости 150 выполняется отложенное построение, если присутствуют табличные переменные, и план запроса не будет построен до тех пор, пока не будет однократно заполнена табличная переменная. Оценка стоимости будет производиться по результатам первого использования табличной переменной, без дальнейших перестроений. Это компромисс между постоянным перестроением, для получения точной стоимости, и полным отсутствием перестроения с постоянной стоимостью 1. Если количество строк остается относительно постоянным, то это хороший показатель (и еще более хороший, если число превышает 1), но может быть менее выгодным, если имеет место большой разброс в количестве строк.
Более глубокий разбор я представил в недавней статье Табличные переменные: Отложенное построение в SQL Server, и Брент Озар тоже говорил об этом в статье Быстрые табличные переменные (И новые проблемы анализа параметров).
Обратная связь по выделяемой памяти в строковом режиме
SQL Server 2017 имеет обратную связь по выделяемой памяти в пакетном режиме, которая подробно описана здесь. По существу, для любого выделения памяти, связанного с планом запроса, включающего операторы пакетного режима, SQL Server оценит память, использованную запросом, и сравнит её с запрошенной памятью. Если запрошенной памяти слишком мало или слишком много, что приведет к сливам в tempdb или пустой трате памяти, то при следующем запуске выделяемая память для соответствующего плана запроса будет скорректирована. Такое поведение либо уменьшит выделяемый объем и расширит параллелизм, либо увеличит его, для улучшения производительности.
Теперь мы получаем такое же поведение для запросов в строковом режиме, под уровнем совместимости 150. Если запрос был вынужден слить данные на диск, то для последующих запусков выделяемая память будет увеличена. Если по факту выполнения запроса потребовалось вполовину меньше памяти, чем было выделено, то для последующих запросов она будет скорректирована в нижнюю сторону. Бретн Озар более подробно описывает это в своей статье Условное выделение памяти.
Пакетный режим для построчного хранения
Начиная с SQL Server 2012, запросы к таблицам с колоночными индексами получили выигрыш от повышения производительности пакетного режима. Улучшение производительности происходят из-за обработчика запросов, выполняющего пакетную, а не построчную обработку. Строки тоже обрабатываются ядром хранилища в пакетах, что позволяет избежать операторов обмена параллелизма. Пол Уайт (@SQL_Kiwi) напомнил мне, что, если использовать пустую таблицу с колоночным хранением, чтобы сделать возможными операции пакетного режима, то обработанные строки будут собраны в пакеты невидимым оператором. Однако этот костыль может свести на нет любые улучшения, полученные от обработки в пакетном режиме. Некоторая информация об этом есть в ответе на Stack Exchange.
При уровне совместимости 150, SQL Server 2019 автоматически выберет пакетный режим в определенных случаях в качестве золотой середины, даже когда нет колоночных индексов. Можно подумать, что почему бы просто не создать колоночный индекс и дело в шляпе? Или продолжить использовать упомянутый выше костыль? Такой подход был распространен и на традиционные объекты с построчным хранением, ибо колоночные индексы, по ряду причин, не всегда возможны, включая ограничения функционала (например, триггеры), издержки при высоконагруженных операциях обновления или удаления, а также отсутствия поддержки сторонних производителей. А от того костыля ничего хорошего ожидать не приходится.
Я создал очень простую таблицу с 10 миллионами строк и одним кластеризованным индексом на целочисленном столбце и запустил этот запрос:
SELECT sa5, sa2, SUM(i1), SUM(i2), COUNT(*)
FROM dbo.FactTable
WHERE i1 > 100000
GROUP BY sa5, sa2
ORDER BY sa5, sa2;
План отчетливо показывает поиск по кластеризованному индексу и параллелизм, но ни слова о колоночном индексе (что и показывает SentryOne Plan Explorer):
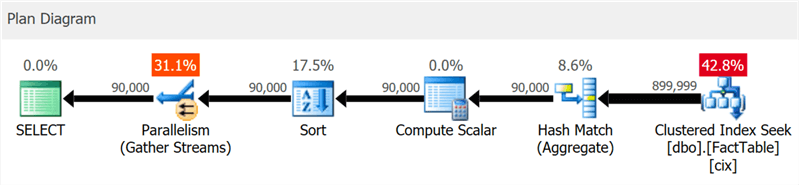
Но если копнуть немного глубже, то можно увидеть, что практически все операторы выполнялись в пакетном режиме, даже сортировка и скалярные вычисления:
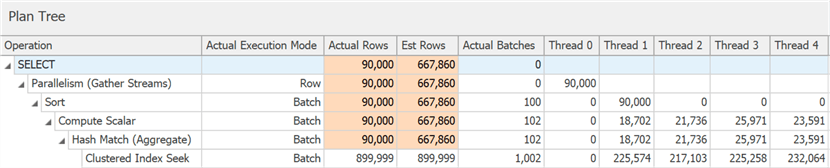
Вы можете отключить эту функцию, оставшись на более низком уровне совместимости, путем изменения конфигурации базы данных или с помощью подсказки DISALLOW_BATCH_MODE в запросе:
SELECT … OPTION (USE HINT ('DISALLOW_BATCH_MODE'));
В этом случае появляется дополнительный оператор обмена, все операторы выполняются в построчном режиме, а время выполнения запроса увеличивается почти в три раза.

До определенного уровня можно увидеть это в диаграмме, но в дереве подробностей плана можно также увидеть влияние условия отбора, неспособного исключить строки, пока не произошла сортировка:
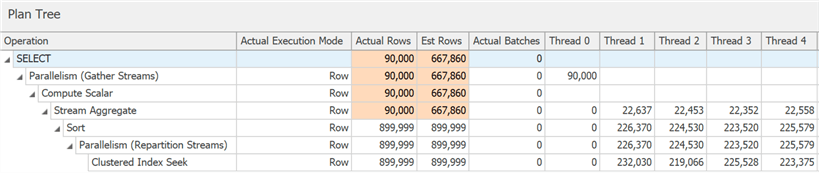
Выбор пакетного режима – не всегда удачный шаг – эвристика, включенная в алгоритм принятия решения, учитывает количество строк, типы предполагаемых операторов и ожидаемую выгоду пакетного режима.
APPROX_COUNT_DISTINCT
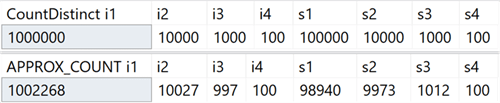
Эта новая агрегатная функция предназначена для сценариев работы с хранилищами данных и является эквивалентом COUNT(DISTINCT()). Однако вместо того, чтобы выполнять дорогостоящие сортировки, для определения фактического количества, новая функция полагается на статистику, чтобы получить относительно точные данные. Нужно понимать, что погрешность лежит в пределах 2% от точного количества, и в 97% случаев, являющихся нормой для высокоуровневой аналитики, — это значения, отображаемые на индикаторах или используемые для быстрых оценок.
В своей системе я создал таблицу с целочисленными столбцами, включающими уникальные значения в диапазоне от 100 до 1 000 000, и строковыми столбцами, с уникальными значениями в диапазоне от 100 до 100 000. В ней не было никаких индексов, кроме кластеризованного первичного ключа в первом целочисленном столбце. Вот результаты выполнения COUNT(DISTINCT()) и APPROX_COUNT_DISTINCT() по этим столбцам, из которых можно увидеть небольшие расхождения (но всегда в пределах 2%):
Выигрыш огромен, если есть ограничения по памяти, что относится к большинству из нас. Если посмотреть на планы запросов, в этом конкретном случае, то можно увидеть огромную разницу в потреблении памяти оператором хэш-соответствия (hash match):
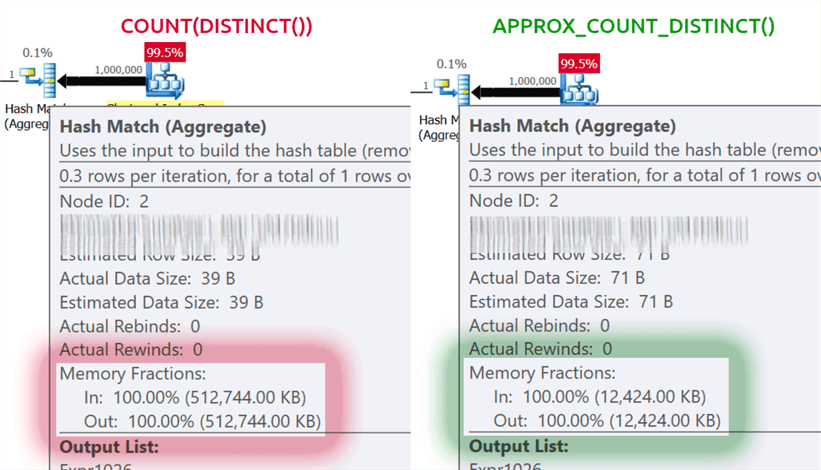
Обратите внимание, что вы, как правило, будете замечать только значительные улучшения производительности, если вы уже привязаны к памяти. В моей системе выполнение длилось немного дольше из-за сильной загрузки ЦП новой функцией:

Возможно, разница была бы более существенной, если бы у меня были более крупные таблицы, меньше памяти, доступной SQL Server, более высокий параллелизм или какая-либо комбинация из вышеперечисленного.
Подсказки для использования уровня совместимости в пределах запроса
У Вас есть особенный запрос, который работает лучше под определенным уровнем совместимости, отличным от текущей базы данных? Теперь это возможно, за счет новых подсказок запроса, поддерживающих шесть различных уровней совместимости и пять различных моделей оценки количества элементов. Ниже приведены доступные уровни совместимости, пример синтаксиса и модель уровня совместимости, которая используется в каждом случае. Посмотрите, как это влияет на оценки, даже для системных представлений:

Короче говоря: нет больше необходимости запоминать флаги трассировки, или задаваться вопросом нужно ли беспокоиться о том, распространяется ли исправление TF 4199 для оптимизатора запросов, или оно было отменено каким-то другим пакетом обновления. Обратите внимание, что эти дополнительные подсказки недавно также были добавлены для SQL Server 2017 в накопительном обновлении №10 (подробности смотрите в блоге Педро Лопеса). Вы можете увидеть все доступные подсказки с помощью следующей команды:
SELECT name FROM sys.dm_exec_valid_use_hints;
Но не забывайте, что подсказки — это исключительная мера, они часто подходит для того, чтобы выйти из затруднительной ситуации, но не должны планироваться для использования в долгосрочной перспективе, так как с последующими обновлениями их поведение может измениться.
Поиск и устранение неполадок в работе
Упрощенное профилирование по умолчанию
Для понимания этого улучшения требуется вспомнить несколько моментов. В SQL Server 2014 появилось DMV представление sys.dm_exec_query_profiles, позволяющее пользователю, выполняющему запрос, собирать диагностическую информацию обо всех операторах на всех участках запроса. Собранная информация становится доступной после завершения выполнения запроса и позволяет определить, какие операторы на самом деле затратили основные ресурсы и почему. Любой пользователь, невыполнявший конкретный запрос, мог получить эти данные для любого сеанса, в котором была включена инструкция STATISTICS XML или STATISTICS PROFILE, или для всех сеансов, с помощью расширенного события query_post_execution_showplan, хотя это событие, в частности, может повлиять на общую производительность.
В Management Studio 2016 добавлен функционал, позволяющий отображать потоки данных, проходящих через план запроса, в режиме реального времени на основе информации, собранной от DMV, что делает его еще более мощным для поиска и устранения проблем. Plan Explorer также предлагает возможность визуализации данных, проходящих через запрос, как в реальном режиме времени, так и в режиме воспроизведения.
Начиная с SQL Server 2016 с пакетом обновления 1 (SP1), можно также включить облегченную версию сбора этих данных по всем сеансам, с помощью флага трассировки 7412 или расширенного свойства query_thread_profile, что позволяет сразу получить актуальную информацию о любом сеансе, без необходимости что-либо в нем включать в явном виде (в частности вещи, которые отрицательно влияют на производительность). Более подробно об этом рассказано в блоге Педро Лопеса.
В SQL Server 2019 эта функция включена по умолчанию, поэтому не нужно запускать никаких сеансов с расширенными событиями или использовать какие-то флаги трассировки и инструкций STATISTICS ни в каком запросе. Достаточно просто посмотреть на данные от DMV в любое время для всех параллельных сеансов. Но есть возможность и отключить данный режим, с помощью LIGHTWEIGHT_QUERY_PROFILING, однако данный синтаксис не работает в CTP 2.0 и будет исправлен в последующих редакциях.
Статистика кластеризованного колоночного индекса теперь доступна в клонированных БД
В текущих версиях SQL Server, при клонировании базы данных, используется только оригинальная статистика объекта из кластеризованных колоночных индексов, без учета обновлений, произведенных в таблице после ее создания. Если Вы используете клон для настройки запросов и прочего тестирования производительности, которое строятся на оценках мощности, то эти примеры могут не подойти. Парикшит Савьяни описал ограничения в этой публикации и предоставил временное решение – перед созданием клона нужно сделать скрипт, который выполняет DBCC SHOW_STATISTICS … WITH STATS_STREAM для каждого объекта. Это затратно и, безусловно, об этом легко забыть.
В SQL Server 2019 эта обновленная статистика будет доступна в клоне автоматически, так что можно тестировать различные сценарии запросов и получать объективные планы, основанные на реальной статистике, без ручного запуска STATS_STREAM для всех таблиц.
Прогноз сжатия для колоночного хранения
В текущих версиях у процедуры sys.sp_estimate_data_compression_savings есть следующая проверка:
if (@data_compression not in ('NONE', 'ROW', 'PAGE'))
Это означает, что она позволяет проверять сжатие строки или страницы (или видеть результат удаления текущего сжатия). В SQL Server 2019 такая проверка теперь выглядит так:
if (@data_compression not in ('NONE', 'ROW', 'PAGE', 'COLUMNSTORE', 'COLUMNSTORE_ARCHIVE'))
Это отличная новость, потому что позволяет примерно предсказывать влияние добавления колоночного индекса в таблицу, в которой его нет, или преобразовывать таблицы или разделы в еще более сжатый формат колоночного хранения, без необходимости восстанавливать эту таблицу в другой системе. У меня была талица с 10 млн строк, для которой я выполнил хранимую процедуру с каждым из пяти параметров:
EXEC sys.sp_estimate_data_compression_savings
@schema_name = N'dbo',
@object_name = N'FactTable',
@index_id = NULL,
@partition_number = NULL,
@data_compression = N'NONE';
-- repeat for ROW, PAGE, COLUMNSTORE, COLUMNSTORE_ARCHIVE
Результаты:

Как и в случае с другими типами сжатия, точность полностью зависит от имеющихся строк и репрезентативности остальных данных. Тем не менее, это довольно мощный способ получить предположительные результаты без особого труда.
Новая функция для получения информации о странице
Долгое время для сбора информации о страницах, содержащих секцию, индекс или таблицу, использовались команды DBCC PAGE и DBCC IND. Но они недокументированные и неподдерживаемые, и бывает достаточно утомительно автоматизировать решение задач, связанных с несколькими индексами или страницами.
Позже появилась динамическая административная функция (DMF) sys.dm_db_database_page_allocations, которая возвращает набор, представляющий все страницы в указанном объекте. Все еще недокументированная и имеющая недочеты, которые могут стать реальной проблемой на больших таблицах: даже для получения информации об одной странице, он должен прочесть всю структуру, что может быть довольно затратно.
В SQL Server 2019 появилась еще одна DMF — sys.dm_db_page_info. В основном она возвращает всю информацию о странице, без накладных расходов на DMF распределения. Однако чтобы использовать функцию в текущих сборках, нужно заранее знать номер искомой сраницы. Возможно, такой шаг был сделан намеренно, т.к. это единственный способ, позволяющий обеспечить производительность. Так что если Вы пытаетесь определить все страницы в индексе или таблице, то по-прежнему необходимо использовать DMF распределения. В следующей статья я опишу этот вопрос более подробно.
Безопасность
Постоянное шифрование с использованием безопасной среды (анклава)
На данный момент, постоянное шифрование защищает конфиденциальные данные при передаче и в памяти путем шифрования/расшифровки на каждом конце процесса. К сожалению, это часто приводит к серьезным ограничениям при работе с данными, таким, как невозможность выполнения вычислений и фильтрации, поэтому приходится передавать весь набор данных на сторону клиента, чтобы выполнить, скажем, поиск по диапазону.
Безопасная среда (анклав) — это защищенная область памяти, где такие вычисления и фильтрация могут быть делегированы (в Windows используется безопасность на основе виртуализации) – данные остаются зашифрованными в ядре, но могут быть безопасно расшифрованы или зашифрованы в безопасной среде. Нужно просто добавить параметр ENCLAVE_COMPUTATIONS в первичный ключ, с помощью SSMS, например, установив флажок «Разрешить вычисления в защищенной среде»:
Теперь можно шифровать данные почти мгновенно, по сравнению со старыми способом (в котором мастеру, командлету Set-SqlColumnEncyption или Вашему приложению, пришлось бы полностью получить весь набор из базы данных, зашифровать его, и отправить обратно):
ALTER TABLE dbo.Patients
ALTER COLUMN SSN char(9) -- currently not encrypted!
ENCRYPTED WITH
(
COLUMN_ENCRYPTION_KEY = ColumnEncryptionKeyName,
ENCRYPTION_TYPE = Randomized,
ALGORITHM = 'AEAD_AES_256_CBC_HMAC_SHA_256'
) NOT NULL;
Думаю, что для многих организаций данное улучшение будет главной новостью, однако в текущем CTP некоторые из этих подсистем все еще совершенствуются, поэтому по умолчанию они выключены, но здесь можно посмотреть, как их включить.
Управление сертификатами в диспетчере конфигурации
Управление сертификатами SSL и TLS всегда было болью, и многие люди были вынуждены выполнять утомительную работу, создавать собственные скрипты для развертывания и обслуживания сертификатов своего предприятия. Обновленный диспетчер конфигурации для SQL Server 2019 поможет быстро просмотреть и проверить сертификаты любого экземпляра, найти сертификаты, срок действия которых истекает в ближайшее время, и синхронизировать развертывания сертификатов во всех репликациях в группе доступности или всех узлах в экземпляре отказоустойчивого кластера.
Я не пробовал все эти операции, но они должны работать и для предыдущих версий SQL Server, если управление происходит из диспетчера конфигураций SQL Server 2019.
Встроенная классификация данных и аудит
Команда разработчиков SQL Server добавила в SSMS 17.5 возможность классифицировать данные, позволяющую определить любые столбцы, которые могут содержать конфиденциальную информацию или же противоречить различным стандартам (HIPAA, SOX, PCI, и GDPR, разумеется). Мастер задействует алгоритм, предлагающий столбцы, которые, предположительно, вызовут проблемы, но можно как скорректировать его предложение, удалив эти столбцы из списка, так и добавить свои собственные. Для хранения классификации используются расширенные свойства; Встроенный в SSMS отчет использует ту же информацию для отображения своих данных. Вне отчета эти свойства не столь очевидны.
В SQL Server 2019 появилась новая инструкция для этих метаданных, уже доступная в базе данных SQL Azure, и называющаяся как ADD SENSITIVITY CLASSIFICATION. Она позволяет выполнять то же самое, что и мастер в SSMS, но информация больше не сохраняется в расширенном свойстве, и любое обращение к этим данным автоматически отображается в аудите как новый XML-столбец data_sensitivity_information. Он содержит все типы информации, которые были затронуты во время аудита.
В качестве быстрого примера предположим, что у меня есть таблица для внешних подрядчиков:
CREATE TABLE dbo.Contractors
(
FirstName sysname,
LastName sysname,
SSN char(9),
HourlyRate decimal(6,2)
);
Взглянув на такую структуру становится ясно, что все четыре столбца либо потенциально уязвимы для утечки, либо должны быть доступны только ограниченyому кругу лиц. Тут можно обойтись разрешениями, но как минимум необходимо заострить на них внимание. Таким образом, мы можем классифицировать эти столбцы по-разному:
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.FirstName, dbo.Contractors.LastName
WITH (LABEL = 'Confidential – GDPR', INFORMATION_TYPE = 'Personal Info');
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.SSN
WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'National ID');
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.HourlyRate
WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'Financial');
Теперь, вместо того, чтобы смотреть в sys.extended_properties, можно увидеть их в sys.sensitivity_classifications:

И если мы проводим аудитную выборку (или DML) для этой таблицы, нам не нужно ничего специально менять; после создания классификации, SELECT * занесет в журнал аудита запись об этом типе информации в новый столбец data_sensitivity_information:
<sensitivity_attributes>
<sensitivity_attribute label="Confidential - GDPR" information_type="Personal Info" />
<sensitivity_attribute label="Highly Confidential" information_type="National ID" />
<sensitivity_attribute label="Highly Confidential" information_type="Financial" />
</sensitivity_attributes>
Разумеется, это не решает все вопросы соблюдения стандартов, но это может дать реальное преимущество. Использование мастера для автоматического определения столбцов и перевода вызовов sp_addextendedproperty в команды ADD SENSITIVITY CLASSIFICATION может существенно упростить задачу соблюдения стандартов. Позже, я напишу об этом отдельную статью.
Можно также автоматизировать создание (или обновление) разрешений на основе метки в метаданных – создание динамического SQL скрипта, который запрещает доступ ко всем конфиденциальным (GDPR) колонкам, что позволит управлять пользователями, группам или ролямb. Проработаю этот вопрос в будущем.
Доступность
Возобновляемое создание индекса в режиме реального времени
В SQL Server 2017 появилась возможность приостановить и возобновить перестроение индекса в реальном времени, что может быть очень полезно, если вам нужно изменить количество используемых процессоров, продолжить с момента приостановки после произошедшего отказа или просто ликвидировать пробел между сервисными окнами. Я рассказывал об этой функции в предыдущей статье.
В SQL Server 2019 можно использовать тот же синтаксис для создания индексов в реальном времени, приостановки и продолжения, а также для ограничения времени выполнения (задание времени приостановки):
CREATE INDEX foo ON dbo.bar(blat)
WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 10 MINUTES);
Если этот запрос работает слишком долго, то для приостановки можно выполнить ALTER INDEX в другом сеансе (даже если индекс еще физически не существует):
ALTER INDEX foo ON dbo.bar PAUSE;
В текущих сборках нельзя уменьшить степень параллелизма при возобновлении, как в случае с перестроением. При попытке уменьшить DOP:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 2);
Получим следующее:
Msg 10666, Level 16, State 1, Line 3
Cannot resume index build as required DOP 4 (DOP operation was started with) is not available. Please ensure sufficient DOP is available or abort existing index operation and try again.
The statement has been terminated.
На самом деле, если попробовать это сделать, а затем выполнить команду без дополнительных параметров, то получим ту же ошибку, по крайней мере на текущих сборках. Думаю, что попытка возобновления была где-то зарегистрирована и система хотела ее использовать вновь. Для продолжения необходимо указать корректное (или более высокое) значение DOP:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 4);
Чтобы было понятно: можно увеличить DOP, при возобновлении приостановленного создания индекса, но никак не понижать.
Дополнительная выгода от всего этого в том, что можно настроить операции создания и/или возобновления индексов в реальном времени в качестве режима по умолчанию, используя для новой базы данных предложения ELEVATE_ONLINE и ELEVATE_RESUMABLE.
Создание/перестроение кластеризованных колоночных индексов в реальном времени
В дополнение к возобновляемому созданию индекса мы также получаем возможность создавать или перестраивать кластеризованные колоночные индексы в режиме реального времени. Это существенное изменение, позволяющее больше не тратить время сервисных окон на техническое обслуживание таких индексов или (для большей убедительности) для преобразования индексов из построчных в колоночные:
CREATE TABLE dbo.splunge
(
id int NOT NULL
);
GO
CREATE UNIQUE CLUSTERED INDEX PK_Splunge ON dbo.splunge(id);
GO
CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge
WITH (DROP_EXISTING = ON, ONLINE = ON);
Одно предупреждение: если существующий традиционный кластеризованный индекс был создан в режиме реального времени, то его преобразование в кластеризованный колоночный индекс тоже возможно только в таком режиме. Если он является частью первичного ключа, встроенного или нет…
CREATE TABLE dbo.splunge
(
id int NOT NULL CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED (id)
);
GO
-- or after the fact
-- ALTER TABLE dbo.splunge ADD CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED(id);
Получим такую ошибку:
Msg 1907, Level 16
Cannot recreate index 'PK_Splunge'. The new index definition does not match the constraint being enforced by the existing index.
Сначала необходимо удалить ограничение, чтобы преобразовать его в кластеризованный колоночный индекс, но обе эти операции можно выполнить в реальном времени:
ALTER TABLE dbo.splunge DROP CONSTRAINT PK_Splunge
WITH (ONLINE = ON);
GO
CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge
ON dbo.splunge
WITH (ONLINE = ON);
Это работает, но на крупных таблицах, вероятно, займет больше времени, чем если бы первичный ключ был реализован в виде уникального кластеризованного индекса. Не могу точно сказать, является ли это намеренным ограничением или просто ограничением текущих CTP.
Перенаправление подключения репликации от вторичного сервера к первичному
Эта функция позволяет настроить перенаправление без прослушивания, так что можно переключить соединение на первичный сервер, даже если в строке соединения напрямую указан вторичный. Данную функцию можно использовать когда технология кластеризации не поддерживает прослушивание, при использовании AGs без кластера, или когда имеет место сложная схема перенаправления в сценарии с несколькими подсетями. Это предотвратит подключение от, например, попыток операций записи для репликации, находящейся в режиме только для чтения (и отказов, соответственно).
Разработка
Дополнительные возможности графа
Отношения графа теперь поддерживают оператор MERGE для узла или граничных таблиц, используя предикаты MERGE; теперь один оператор может обновить существующее ребро или вставить новое. Новое ограничение ребер позволит определить какие узлы может соединять ребро.
UTF-8
В SQL Server 2012 была добавлена поддержка UTF-16 и дополнительных символов путем установки сортировки за счет задания имени с суффиксом _SC, типа Latin1_General_100_CI_AI_SC, для использования столбцов в формате Unicode (nchar/nvarchar). В SQL Server 2017 можно импортировать и экспортировать данные в формате UTF-8 из и в эти колонки, с помощью средств типа BCP и BULK INSERT.
В SQL Server 2019 существуют новые параметры сортировки для поддержки принудительного хранения в исходном виде данных UTF-8. Так что можно без проблем создавать колонки типа char или varchar и корректного храненить данные UTF-8, используя новые параметры сортировки с суффиксом _SC_UTF8, как Latin1_General_100_CI_AI_SC_UTF8. Это может помочь улучшить совместимость с внешними приложениями и СУБД, без затрат на обработку и хранение nvarchar.
Пасхалка, которую я нашел
Насколько я помню, пользователи SQL Server жалуются на это смутное сообщение об ошибке:
Msg 8152
String or binary data would be truncated.
В сборках CTP, с которыми я экспериментировал, было замечено интересное сообщение об ошибке, которого не было раньше:
Msg 2628
String or binary data would be truncated in table '%.*ls', column '%.*ls'. Truncated value: '%.*ls'
Я не думаю, что здесь нужно что-то еще; это отличное (хотя и весьма запоздалое) улучшение, и обещает многих сделать счастливыми. Однако эта функциональность не будет доступна в CTP 2.0; я просто даю возможность заглянуть немного вперед. Брент Озар перечислил все новые сообщения, найденные им в текущем CTP, и приправил их несколькими полезными комментариями в своей статье sys.messages: обнаружение дополнительных функций.
Заключение
SQL Server 2019 предлагает хорошие дополнительные возможности, которые помогут улучшить работу с любимой платформой реляционных баз данных, и есть ряд изменений, о которых я не говорил. Энергостойкая память, кластеризация для служб машинного обучения, репликация и распределенные транзакции в Linux, Kubernetes, коннекторы для Oracle / Teradata / MongoDB, синхронные репликации AG поднялись до поддержки Java (реализация аналогична Python/R) и, что не менее важно, новый рывок, под названием «Кластер больших данных». Для использования некоторых из этих функций необходимо зарегистрироваться с помощью этой EAP формы.
Предстоящая книга Боба Уорда, Pro SQL Server on Linux — Including Container-Based Deployment with Docker and Kubernetes, может дать некоторые подсказки о ряде других вещей, которые вскоре появятся. И эта публикация Брента Озара говорит о возможном грядущем исправлении скалярной определяемой пользователем функции.